파워 오브 데이터베이스 ( 가장 쉬운 데이터베이스 설계를 위한 지침서, 마이클 J. 헤르난데즈 저/송현호, 황규용 역 )의 3장을 공부하고 요약 한 내용입니다.
3. 전문 용어
값 관련 용어
- 데이터
- 데이터베이스에 저장된 값들
- 다른 프로세스에 의해 변경되기 전까지는 같은 상태를 유지하기 때문에 정적임
- 정보와는 다름
- 정보
- 데이터 중에서 일을 하거나 분석을 하기 위해 특정한 방법을 통해 의미 있고 실용적으로 재생성한 것
- 지속적으로 데이터베이스에 저장된 데이터 사이의 관계를 변경하고 수많은 방법을 통해 데이터를 보여주고 가공할 수 있기 때문에 매우 동적
- SQL문의 결과로 확인 할 수 있음
- 데이터를 몇 가지 방법으로 가공해서 의미있는 결과로 바꿔야만 정보라 할 수 있다
- 데이터는 저장하는 것이고, 정보는 찾는것
데이터베이스에 적절한 데이터가 존재하고, 데이터베이스가 의미있는 정보를 보여줄 수 있어야 의미 있는 데이터베이스 설계이다.
- 널 ( Null )
- 없거나, 알려지지 않은 값
- 0이나 하나 이상의 공백문자와는 다른 것
- 0은 다양한 의미를 가질 수 있다 ( 잔액의 상태, 재고 숫자 … )
- 하나 이상의 공백 문자열은 SQL에서 의미를 가질 수 있음 ( 공백도 유효한 문자로 인지 )
- 빈 문자열 ( ‘’ )역시 유효한 문자로 인지 ( 이름에 쓰인다면 Middle name이 없다는 뜻으로도 쓰일 수 있음 )
- 발생할 수 있는 이유
- 누락값
- 주로 사람의 실수로 인해 발생
- 알려지지 않은 값
- 필드에 필요한 특정 값이 정의되지 않은 경우
- 한 필드값이 다른 필드값의 부재를 야기하는 경우
- 값이 없는 경우라면 Null 보단 다른 값 사용 ( N/A 나, Not Applicable ) ( ex_ 대머리의 머리색 … )
- 누락값
- Null 값의 문제점
- 수학적 연산에 부정적인 영향을 미침
- 어떠한 수학적인 연산을 하더라도, 연산에 Null 이 포함되면, 결과값은 Null 이다.
- 오류를 알려주지 않기 때문에 추적도 불가능
- 통계값을 낼 때도 Null이 있는 데이터 값이 무시된 결과가 나올 것
- 수학적 연산에 부정적인 영향을 미침
구조 관련 용어
- 테이블
- 데이터는 테이블로 인식되는 관계에 저장함
- 각 관계는 튜플(레코드)과 속성(필드)으로 구성됨
- 각 테이블은 항상 하나의 특정 주제를 나타냄
- 레코드와 필드의 논리적 순서는 절대 중요치 않음
- 반드시 PK가 하나 이상 존재 해야함
- 객체 / 이벤트를 기록 할 수 있음
- 객체
- 대상이 객체인 테이블은 유형의 사물을 담는다.
- 조종사, 상품, 기계, 학생 등은 객체가 대상인 테이블
- 이벤트
- 대상이 이벤트인 테이블은 기록하고자 하는 특성들을 특정 시간대에 발생하는 것을 표시하는 테이블
- 재판 공정, Transaction, 실험실의 테스트 등은 이벤트가 대상인 테이블
- 객체
- 데이터를 저장하는 테이블을 데이터 테이블 이라고 부르며, 일반적으로 사용하는 테이블임 ( 데이터 수정빈도 높음 )
- 데이터 무결성을 보장할 때 사용하는 데이터를 저장하는 테이블을 검증 테이블, 룩업 테이블도 존재
- 주로 도시명, 기술 범주, 상품 코드, 프로젝트 고유 번호와 같은 자료들을 나타냄
- 데이터의 수정 빈도 낮음
- 필드 ( 속성 )
- 데이터베이스의 가장 작은 구조, 테이블이 가지고 있는 대상의 특성을 표현
- 데이터를 실질적으로 저장하는 구조
- 필드의 이름은 어떤 데이터가 들어가는지 직관적으로 알 수 있도록 짓는것이 매우 좋다.
- 피해야할 필드 구성
- 다중 값 필드
- 하나의 필드에 여러개의 값이 들어가는 형태
- 다중 구성 필드
- 하나의 필드가 여러 의미를 가지는 경우
- 계산된 필드
- 여러 필드값의 계산된 결과값을 갖는 필드
- 다중 값 필드
- 레코드 ( 튜플 )
- 테이블 대상에 대한 유일한 값을 표시 ( PK로 구분 )
- 필드값의 집합으로 구성됨
- 뷰
- 하나 이상의 테이블에서 여러 필드들을 혼합하여 만든 가상 테이블
- 뷰를 구성하는 테이블들을 기반 테이블 이라고 지칭
- 뷰에 직접 데이터를 넣거나, 수정하지 않기 때문에 가상 테이블로 불림
- 지원하는 RDBMS도 있으나, 지원 하지 않는 경우도 존재
- 지원한다면, 뷰의 장점
- 여러 테이블에 있는 데이터에 대한 작업 수행 가능 ( 관계를 갖고 연결 되어 있는 경우에만 가능 )
- 여러 테이블에 있는 특정 필드를 보거나 조작하는 것을 방지하도록 해줌 → 보안적 이점
- 데이터 무결성 구현하는데 도움이 됨 ( 이런 목적으로 사용하는 뷰를 검증 뷰 라고 함 )
- 키
- 기본 키 ( Primary Key ), 외래 키 ( Foreign Key )가 존재
- 기본 키는 하나 혹은 여러개의 필드의 조합으로 구성 될 수 있으며, 여러개의 필드로 구성된 PK를 복합 키라 지칭
- 기본키
- 기본 키의 값은 전체 데이터베이스 중 특정 레코드 식별 가능
- 기본 키의 필드는 전체 데이터베이스 중 특정 테이블 식별
- 기본 키는 테이블 수준의 무결성을 강제하고, 데이터베이스에 있는 다른 테이블과 관계를 설정할 수 있도록 해줌
- 모든 테이블은 기본 키를 반드시 가지고 있어야함
- 외래키
- PK가 다른 테이블로 넘어왔다는 데에서 유래한 이름
- 두 테이블 사이의 관계를 설정 할 수 있도록 도와줌
- 관계 수준의 무결성을 보장하는데 사용 됨
- 외래 키의 값이 참조하는 쪽의 PK의 값과 반드시 일치해야 하기 때문에, 기록들이 항상 적절하게 연결 되어 있도록 도와줌
- 고아 레코드가 발생하는것 막아줌
- 고객이 없는 주문 레코드는 존재 할 수 없음 ( 하면 안됨 )
- 인덱스
- RDBMS의 데이터 처리 속도를 향상 시키기 위한 구조
- 절대적으로 필요한 것은 아님 ( 인덱스와 키를 혼동하지 말자 )
- 테이블의 레코드를 식별할 때 사용하는 논리적인 구조 → 키
- 데이터 처리 속도를 최적화 할 때 사용하는 물리적 구조 → 인덱스
관계 관련 용어
- 관계
- 두 테이블의 레코드 사이에 몇 가지 방법을 통해 연관을 지을 수 있을 때 두 테이블 사이엔 관계가 존재
- PK와 FK의 집합을 통해 관계 설정 가능
- 연결 테이블 이라고 불리는 세번째 테이블을 통해 설정 할 수도 있음
- 관계를 통해 다중 테이블 뷰를 만드는 것이 가능
- 불필요한 데이터를 줄이고, 중복 데이터를 제거 함으로써 데이터 무결성 보장
- 관계의 유형
- 기수 ( Cardinality )의 유형은 1대 1, 1대 다, 다대 다 로 세가지 존재
- 1대 1관계
- 첫번째 테이블의 레코드와 두번째 테이블의 레코드가 각 한개에만 연결되어 대응되어 있다면 일대일 관계로 칭함
- 부모 / 자식 관계의 구성
- 부모 테이블의 PK값을 자식 테이블의 FK값으로 사용 ( 자식 테이블에서는 가져온 FK의 값을 PK로 써도 무방 ( 1대 1이니까 )) 2. 1대 다 관계
- 첫번째 테이블의 레코드가 두번째 테이블의 레코드에 여러개 연결 되지만, 두번째 테이블의 레코드는 첫번쨰 테이블의 레코드에 오직 하나만 연결되는 경우
- 부모 / 자식 관계의 구성 가능
- 부모 테이블의 PK값을 자식 테이블의 FK값으로 사용 3. 1대 다 관계
- 첫번째 테이블의 레코드가 두번째 테이블에 있는 다수의 레코드와 연결 될 수 있고, 두번째 테이블에 있는 레코드가 첫번째 테이블에 있는 다수의 레코드와 연결 될 수 있는 경우
- 연결 테이블을 통해 설정
- 한 개의 테이블에서 다른 테이블에 있는 레코드들을 연결하는 것을 쉽게 도와줌
- 관련된 데이터를 추가 / 삭제 / 수정 하는데 아무런 문제가 없도록 도와줌
- 각 테이블의 PK값을 복사 하고 새로운 테이블을 형성
- 각 테이블의 PK값의 조합은 연결 테이블의 조합 PK값이 됨
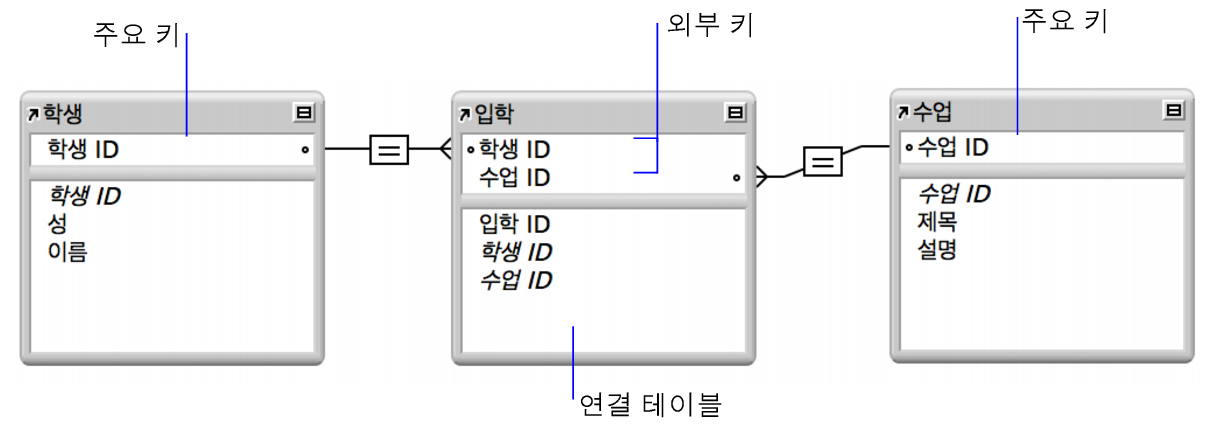
출처 : 다대다 관계
- 기수 ( Cardinality )의 유형은 1대 1, 1대 다, 다대 다 로 세가지 존재
- 참여의 유형
- 관계 내의 테이블의 참여는 필수적 / 선택적 일 수 있음
- 만일 테이블 B에 레코드를 넣기 전에 테이블 A에 적어도 하나의 레코드를 넣어야 한다면 테이블 A의 참여는 필수적
- 만일 테이블 B에 레코드를 넣기 전에 테이블 A에 어떠한 레코드도 넣을 필요가 없다면 테이블 A의 참여는 선택적
- 학생 레코드를 만들 때, 학생 레코드에 학교 데이터가 반드시 존재 해야한다면 학교 테이블의 참여는 필수적, 넣을 필요가 없다면 선택적
- 참여의 정도
- 특정 테이블이 관련된 테이블에 있는 한 개의 레코드와 연결 되어야 하는 최소 / 최대 레코드 개수를 결정
최솟값, 최댓값의 형식으로 표기- 대리인이 고객을 여덣명 이상 관리 할 수 없고, 고객은 대리인이 반드시 필요하다면 참여는
1, 8로 표시
무결성 관련 용어
- 필드 명세 ( 도메인 )
- 필드의 모든 요소를 표시
- 필드의 일반적인, 물리적인, 논리적인 유형의 요소들을 모두 포함
- 일반적인 요소 : 필드와 관련된 가장 기본적인 정보 ( 필드 이름, 상세 설명, 부모 테이블 …. )
- 물리적인 요소 : 필드를 구성하는 방법과 이 필드를 사용하는 사람들에게 표시하는 방법을 결정 ( 데이터 유형, 길이, 출력 양식 … )
- 논리적인 요소 : 필드에 저장되는 값을 표시 ( 요청 값, 값의 범위, 기본 값 … )
- 데이터 무결성
- 데이터베이스에 있는 데이터의 유효성, 일관성, 정확성에 관련이 있음
- 무결성 수준이 높아야만 데이터베이스의 정보를 믿을 만 함
- 제일 중요 정말 중요
- 무결성 종류
- 테이블 수준의 무결성 ( 엔터티 무결성 )
- 테이블 내에 중복된 레코드가 없어야 함
- 테이블 내의 각 레코드를 식별하는 필드 ( PK )가 유일한 값을 가져야 하고, Null이 아님을 보장
- 필드 수준의 무결성 ( 도메인 무결성 )
- 모든 필드의 구조가 잘 되어 있음
- 이각 필드에 있는 값의 유효성, 일관성, 정확성이 확보 되었는지와 같은 유형의 필드들이 일관성 있게 정의 되었는지 확인
- 관계 수준의 무결성 ( 참조 무결성 )
- 테이블 사이의 관계의 적절성과 테이블에 있는 레코드들이 데이터가 다른 테이블에서 입력되거나, 수정되거나, 삭제될 때 마다 동기화 여부 보장
- 업무 규칙
- 조직이 데이터를 인지하고 사용하는 방법에 따라 데이터베이스의 특정 측면에 제약을 줌
- 업무 규칙이 무결성에 영향을 주기 때문에 업무 규칙을 정할 때 세가지 무결성을 고려 해야함
- 테이블 수준의 무결성 ( 엔터티 무결성 )
"Database" 카테고리의 최근 포스팅
카테고리 모든 글 보기| Database - (4) 설계 프로세스의 개념적인 개요 | 2020. 07. 23 |
|---|---|
| Database - (3) 데이터베이스 용어 | 2020. 07. 22 |
| Database - (2) 데이터베이스 설계 목적 | 2020. 07. 21 |
| Database - (1) 관계형 데이터베이스 (RDB) | 2020. 07. 20 |