운영체제 스터디 도중 쉽게 배우는 운영체제를 읽고 요약한 내용입니다. 자세한 내용은 책을 구매하여 확인 부탁드립니다.
7. 물리 메모리 관리
메모리 관리의 개요
메모리 관리의 복잡성
- 메모리는 1B 단위로 나뉨
- 1B단위로 나뉜 각 영역은 메모리 주소를 구분하는데, 0번지 부터 시작
- CPU는 메모리에 데이터를 쓰거나 / 가져오기 위해 MAR ( Memory Address Register )를 사용
- MAR에 필요한 메모리 주소를 넣으면, 데이터를 메모리에서 가져오거나, 메모리에 옮길 수 있음
- 일괄 처리 시스템에서는 메모리에 하나의 작업만 처리 했기 때문에, 메모리 관리가 어렵지 않았으나, 시분할 시스템에서는 운영체제를 포함한 모든 응용프로그램이 메모리에 올라와 실행되기 때문에 관리가 복잡 ( 도마에 올라간 재료가 하나 / 여러개 임을 상상하면 쉬움 )
- 메모리에는 운영체제도 올라 와 있음을 기억 !
- 메모리 관리의 이중성
- 프로세스는 메모리리를 독차지 하려 하고, 메모리 관리자 입장에선 되도록 관리를 효율적으로 하고자 함
- 프로세스 입장에서 작업의 편리함과 관리자 입장에서 관리의 편리함이 충돌을 일으키는 일
- 프로그램을 메모리에서 실행하는 이유
- SSD를 사용하면 안되나 ? → 가격이 비쌈
- CPU속도와 동일한 속도로 작업을 처리하는 캐시메모리도 작지만 속도가 빠름 ( 가격이 비쌈 )
컴파일러 / 인터프리터
- 프로그래머가 고급 언어 ( 인간이 이해할 수 있는 개발 언어 ) 작성 된 코드를, 컴퓨터에서 실행 가능한 코드로 변경 하는 작업이 필요함
- 언어 번역 프로그램
- 고급 언어 ( 사용자가 이해하기 쉽게 프로그래밍 할 수 있는 언어 ( java / c … )로 작성 한 소스코드를 컴퓨터가 실행 할 수 있는 기계어로 번역 해주는 프로그램
- 언어 번역 프로그램의 일종으로 컴파일러 / 인터프리터가 존재
- 컴파일러
- 소스코드를 컴퓨터가 실행 할 수 있는 기계어로 번역 한 후 한꺼번에 실행
- 윈도우에서 실행 가능한 확장자의 이름은 exe인 경우가 잦은데, 이는 컴파일러가 번역 한 기계어 코드의 확장자가 exe 라는뜻
- 요리 예제
- 요리 레시피를 보고, 전체 레시피를 훑어보며 오류나 불필요한 내용이 있는지 살펴봄
- 예를들어 양배추가 소스 만드는데 필요하지만 준비 재료에 적혀있지 않다면 컴파일에러를 띄워 요리사에게 에러를 노출시킴
- 또 양파를 써는 과정에서 양파를 1개씩 써는 작업이 3번이 적혀 있다면 양파 3개를 한번에 썰도록 레시피를 최적화 하는 작업을 거침
- 또 필요하지 않은 재료가 준비물에 적혀 있다면 경고 메세지를 요리사에게 띄워 줄 수 있음
- 목적
- 실행하기 전에 코드를 점검하여 오류를 수정하고 최적화 → 빠른 실행파일을 만드는것이 목적 !
- 오류 발견
- 소스코드에서 오류를 발견하여 실행 시 문제가 없도록 하는 것
- 심벌 테이블을 사용 !
- 심벌 테이블 : 변수 선언부에 명시한 각 변수의 이름과 종류를 모아놓은 테이블
- 선언하지 않은 변수를 사용하지는 않았는지, 변수에 다른 종류의 데이터를 저장하지는 않았는지 확인 할 수 있음
- 코드 최적화
- 양파 1개를 썰어 볶는 작업이 두번 서술되어 있다면 2개를 썰어 볶는 작업으로 합칠 수 있음
- 또 사용되지 않는 불필요한 재료들도 삭제 할 수 있음
- 컴파일 과정
- 소스코드 작성 및 컴파일
- 프로그래머가 작성 한 코드를 0 / 1 로 이루어진 목적 코드 ( object code )로 변환한다.
- 목적 코드와 라이브러리 연결
- 라이브러리에서 가져와 사용한 함수의 기계어 코드를 1번의 과정에서 생성한 목적코드에 삽입하는 과정
- C언어에서 printf()함수를
라이브러에서 가져와 목적 코드에 삽입하는 단계
- 동적 라이브러리를 포함하여 최종 실행
- 동적 라이브러리 ?
- 라이브러리에서 가져 온 코드를 활용( 위 2번의 작업 까지 )하여 실행 파일을 생성 한 이후엔, 라이브러리에서 가져 온 코드의 변경에 대응 할 수 없는 상태이다. ( 이미 라이브러리안의 코드를 가져와 실행파일에 삽입 되어 있기 떄문 )
- 따라서 라이브러리의 업데이트나, 코드 변경 사항에 반응 할 수 없다는 단점을 보완하고자, 라이브러리에 있는 코드의 실제 구현체는 비워두고, 실행 시 동적으로 라이브러리속에서 해당 코드를 가져오는 작업을 진행 할 수 있다.
- 이때 실행할 때 삽입되는 함수를 가진 라이브러리를 동적 라이브러리 라고 칭한다.
- 동적 라이브러리를 활용하면, 라이브러리 속 함수가 변경되도라도 새로 컴파일 할 필요 없이 라이브러리만 변경하여 사용하여 주면 된다.
- DLL ( Dynamic Link Loader )로 칭하기도 함 - 여러 프로그래머 ( A, B, C )가 작업 한 것을 합치려고 할 때는, A, B, C가 작업 한 결과물을 컴파일 한 목적 코드를 합쳐 컴파일 하는 것이 수월함 ( 분할 컴파일이라 칭함 )
- 목적 코드가 만들어 졌다는 것 자체가, 소스코드의 오류 검증과 최적화가 이루어 진 상태라는 것을 의미하기 때문 - 변수와 메모리 할당
1
2
3char str = 'a'; int vol = 1234; float pi = 3.14;- 기계어는 메모리 주소를 사용
- char str = ‘a’;는 기계어에서는 메모리 주소 0번지에
a를 넣으라는 명령으로 번역 - 컴파일러는 0번지에
a를 넣고, 이곳을 문자형이 들어가는 공간으로 기억 - char / int / float는 보관 하려는 자료의 형태를 나타낼 뿐 아니라, 사용하려는 메모리의 크기를 나타내기도 하고 이를 기반으로 심벌 테이블을 생성 함
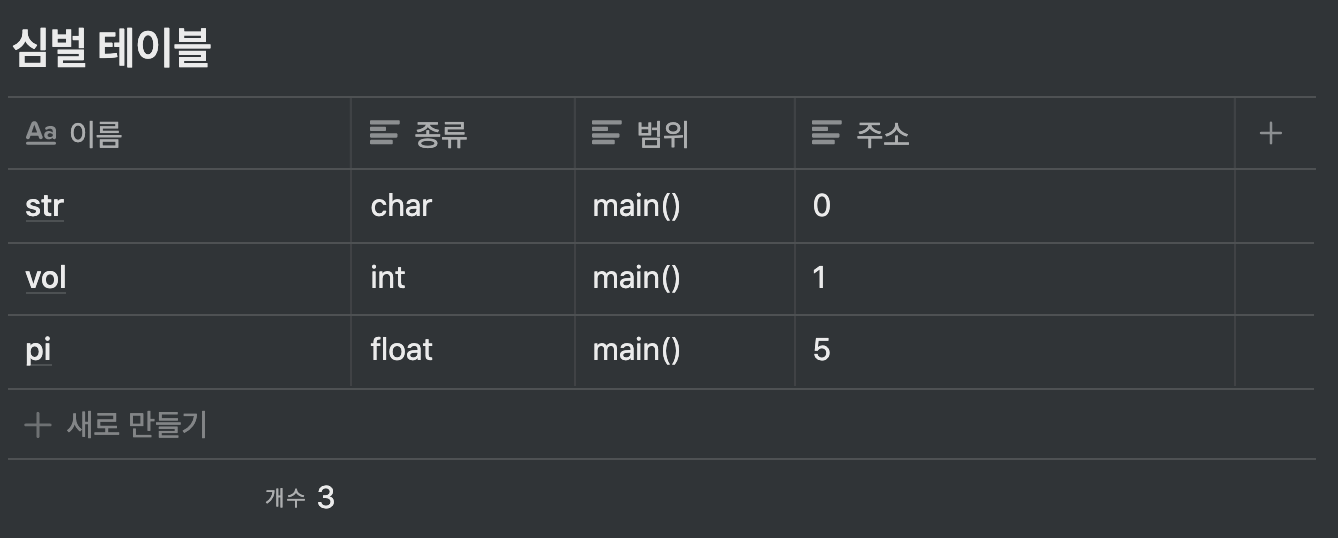
- 위 테이블에서 범위는, 각 변수를 사용 할 수 있는 영역 ( scope )를 나타냄
- 컴파일러는 변수를 사용 할 때 마다, 범위를 벗어나지는 않았는지 체크함
- 변수 종류마다 크기가 정해져 있기 때문에, 변수의 시작 주소만 명시하면 그 크기는 자동으로 정해짐
- 위를 종합해보자면, 변수는 메모리 주소와 같은 말이다
- 메모리 주소는 프로그래머가 기억하고 읽기 힘드므로, 메모리 주소에 프로그래머가 읽기 편한 이름을 지어 변수로 사용 하는것
- 동적 라이브러리 ?
- 소스코드 작성 및 컴파일
- 인터프리터
- 소스코드를 한 행씩 번역하여 실행
- 요리 예제
- 요리 레시피를 보고, 요리 레시피에 적힌 대로 위에서 아래로 한줄 씩 읽어가며 요리를 완성하는 과정
## 메모리 관리자의 역할
- 메모리 관리 유닛 이라는 하드웨어가 메모리를 관리한다.
- 가져오기 ( fetch ) / 배치 ( placement ) / 재배치 ( replacement ) 작업을 진행한다.
- 가져오기
- 프로세스와 데이터를 메모리로 가져오는 작업
- 프로세스와 데이터를 모두 가져오는 경우가 많고, 특정 상황에서는 일부만 가져와 사용하기도 함
- 용량이 큰 동영상 플레이 같은 경우, 플레이어는 전부 가져와 실행하지만 동영상은 필요할 때 마다 수시로 가져와 실행하도록 함
- 앞으로 필요 할 것으로 예상되는 것을 미리 가져오기도 함
- 가져오기 정책
- 프로세스가 필요로 하는 데이터를 언제 메모리로 가져 올 지 결정하는 정책
- 요청 할 때 가져오는게 일반적이지만, 미리 가져오는 경우도 존재 ( prefetch )
- 배치
- 가져온 프로세스와 데이터를 메모리의 어떤 부분에 올려 놓을 지 결정하는 작업
- 배치 작업 전에 메모리를 어떤 크기로 자를 것인지가 매우 중요
- 실행되는 프로세스의 크기에 맞게 자르느냐, 그렇지 않느냐 … 에 따라 배치 작업이 크게 달라짐
- 나누어진 메모리의 구역에 따라 프로세스와 데이터를 어떤 위치에 놓을 지 결정하는 것이 배치 작업
- 배치 정책
- 가져온 프로세스를 메모리의 어떤 위치에 올려 놓을지 결정하는 정책
- 메모리를 같은 크기로 자르는 것 → paging / 프로세스에 맞게 자르는것 → segmentation
- 재배치
- 메모리 속 오래된 프로세스를 내보내는 작업
- 새로운 프로세스를 가져와야 하는데, 메모리가 꽉 찼다면 메모리에 있는 프로세스를 하드디스크로 옮겨 놓아야 새로운 프로세스를 가져 올 수 있음
- 재배치 정책
- 어떤 프로세스를 내보낼지 결정하는 정책
- 해당 알고리즘을 교체 알고리즘 이라 칭함
## 메모리 주소
### 32Bit CPU와 64Bit CPU의 차이
- CPU Bit → 한 번에 다룰 수 있는 데이터의 최대 크기
- 32Bit CPU는 한번에 다룰 수 있는 데이터의 최대 크기가 32Bit
- CPU 내부 부품은 모두 이 비트를 기준으로 제작
- 32Bit CPU의 경우 레지스터 / 산술연산자 / 버스의 크기 / 대역폭 등이 모두 32BIt
- 따라서, 메모리 주소 레지스터의 크기도 32Bit
- 메모리 주소 레지스터의 크기가 32Bit이므로, CPU는 접근 할 수 있는 메모리 주소의 범위가 0 ~ 2^32-1 가 되고 총 크기는 2^32Bit, 약 4GB가 된다.
- 따라서 32Bit CPU의 경우 사용 할 수 있는 메모리의 최대 크기는 4GB이다.
- 64Bit의 경우엔 메모리를 $2^{64}$Bit, 약 16,777,216 TB 까지 사용 가능 하다.
### 절대 주소와 상대 주소 차이
- 메모리 영역 구분
- 메모리는 운영체에 영역과 사용자 영역을 구분 할 필요가 있다.
- 운영체제 영역을 고정 해 놓고, 사용자 영역은 운영체제 영역이 끝나는 지점부터 시작 하여 메모리에 적재를 시작 할 수 있다.
- 하지만, 운영체제 영역의 크기가 변할 수 있음에 따라 사용자 영역의 시작 위치도 변경 될 수 있다.
- 따라서, 운영체제 영역을 놔 두고, 사용자 영역을 메모리의 끝을 시작으로 하고, 운영체제 영역의 끝 을 사용자 영역의 끝으로 정할 수 있다.
- 하지만 위의 경우 메모리를 거꾸로 사용하기 위해 주소를 변경하는 일이 쉽지 않아 잘 쓰이지 않는다.
- 운영체제 영역과 사용자 영역을 구분하기 위해서는 경계 레지스터를 사용한다.
- 경계 레지스터 → 운영체제 영역과 사용자 영역의 경계 지점의 주소를 가진 레지스터
- 경계 레지스터를 벗어나는 작업을 요청하는 프로세스가 있으면 그 프로세스를 강제 종료 시킴
- 절대 주소 / 상대 주소
- 사용자 프로세스가 메모리의 사용자영역 400번지에 올라왔다고 가정
- 컴파일 방식을 사용하는 프로그램의 경우 컴파일 시 변수의 주소를 0번지 부터 배정
- 컴파일 할 당시에는 변수가 메모리의 어느 위치에 올라가는지 알 수 없기 때문에 0번지 부터 배정하고, 실제로 실행 할 때 메모리를 변수의 메모리 위치 주소 번지 + 400 번지 ( 사용자 메모리의 시작 지점 ) 형식으로 조정
- 이 때, 400번지가 절대 주소에 해당
- 절대주소
- 메모리 관리자 입장에서 바라 본 주소 이며, 컴퓨터에 꽂힌 메모리의 실제 주소를 의미
- 절대 주소를 사용하면 메모리 관리자는 편하지만, 사용자 프로그램 입장에서는 불편 / 위험
- 상대 주소
- 사용자 프로세스 입장에서 바라본 주소
- 사용자 영역이 시작되는 번지를 0번지로 변경하여 사용하는 주소 지정 방식
- 사용 할 수 없는 영역의 위치를 알 필요가 없고, 주소가 항상 0번지 부터 시작하기 때문에 편리
- 논리 주소 공간 → 상대 주소를 사용하는 주소 공간
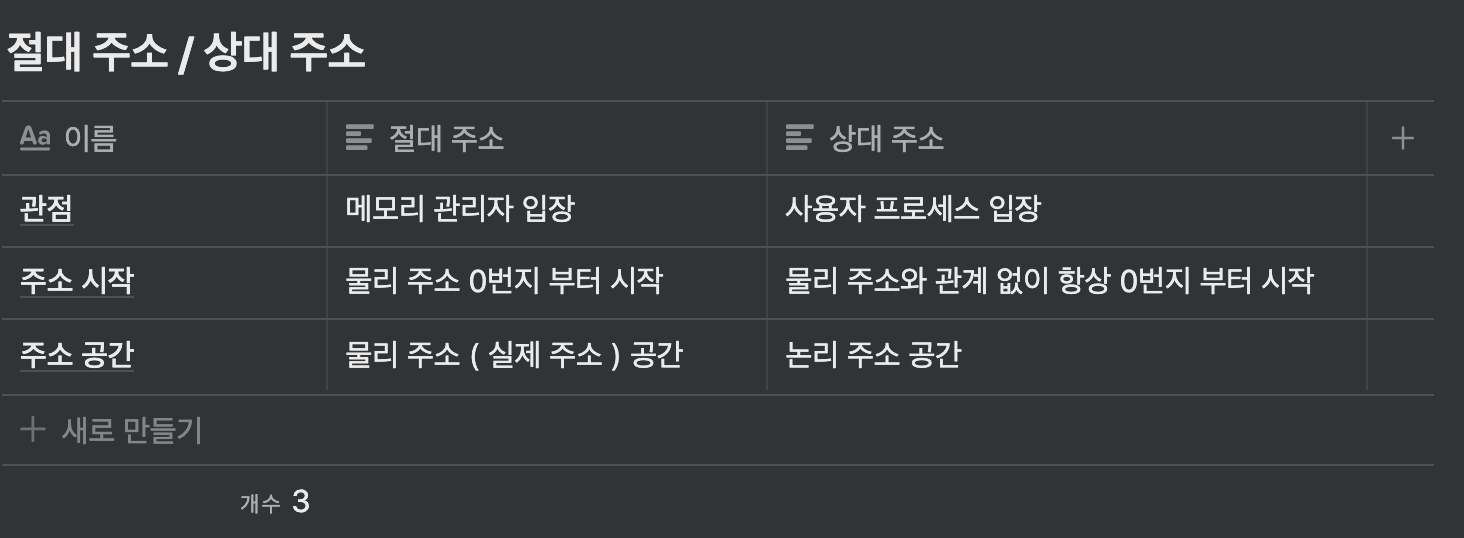
- 상대 주소 값에 재배치 레지스터 값을 더해 절대 주소값을 구함
## 단일 프로그래밍 환경에서의 메모리 할당
- 메모리 오버레이
- 프로그램의 크기가 물미 메모리 크기보다 클 때, 전체 프로그램을 메모리에 가져오는 대신, 적당한 크기로 잘라 가져오는 기법
- 프로그램을 몇개의 모듈로 나누고, 필요 할 때마다 모듈을 메모리에 가져와 사용
- 중요한 모듈만 메모리에 올려 놓고, 나머지는 필요할 때 마다 메모리에 가져와 사용하는 방식
- ex) 아래한글 프로그램을 실행 했을 때, 그림판 / 맞춤법 검사 등의 모듈은 필요 할 때마다 메모리에 올려놓고 사용
- 전체를 모두 올리는 것 보다 속도는 느리지만, 메모리가 프로그램보다 작을 때에도 실행 가능하기 떄문에 유용
- 어떤 모듈을 가져오거나 내보낼 지는 CPU의 프로그램 카운터 레지스터( 앞으로 실행 할 명령어의 위치를 가리키는 레지스터 ) 가 담당
- 스왑
- 스왑영역 : 메모리가 모자라서 쫓겨난 프로세스가 보관되는 영역
- 메모리 오버레이 기법 도중, 필요한 모듈을 가져 오기위해 다른 모듈을 치워야 한다면, 치운 모듈을 보관 하고 있을 장소가 필요
- 원래 있던 하드디스크에 보관 하는 것은 작업이 끝나지 않았고, 언제 다시 사용할 지 모르기 때문에 비효율적
- 스왑 인 → 스왑 영역에서 메모리로 데이터를 가져오는 작업
- 스왑 아웃 → 스왑 영역에서 데이터를 메모리로 가져가는 작업
- 저장장치 관리자가 관리하는 것이 아니라, 메모리 관리자가 관리 함 ( 저장 장치는 장소만 빌려 줌 )
- 스왑 영역 크기 + 실제 메모리 크기 = 사용자가 인지하는 사용 할 수 있는 메모리 영역 크기
- PC에서 절전모드를 실행 했을 때, 실행중이던 프로그램들이 저장되는 곳
## 다중 프로그래밍 환경에서의 메모리 할당
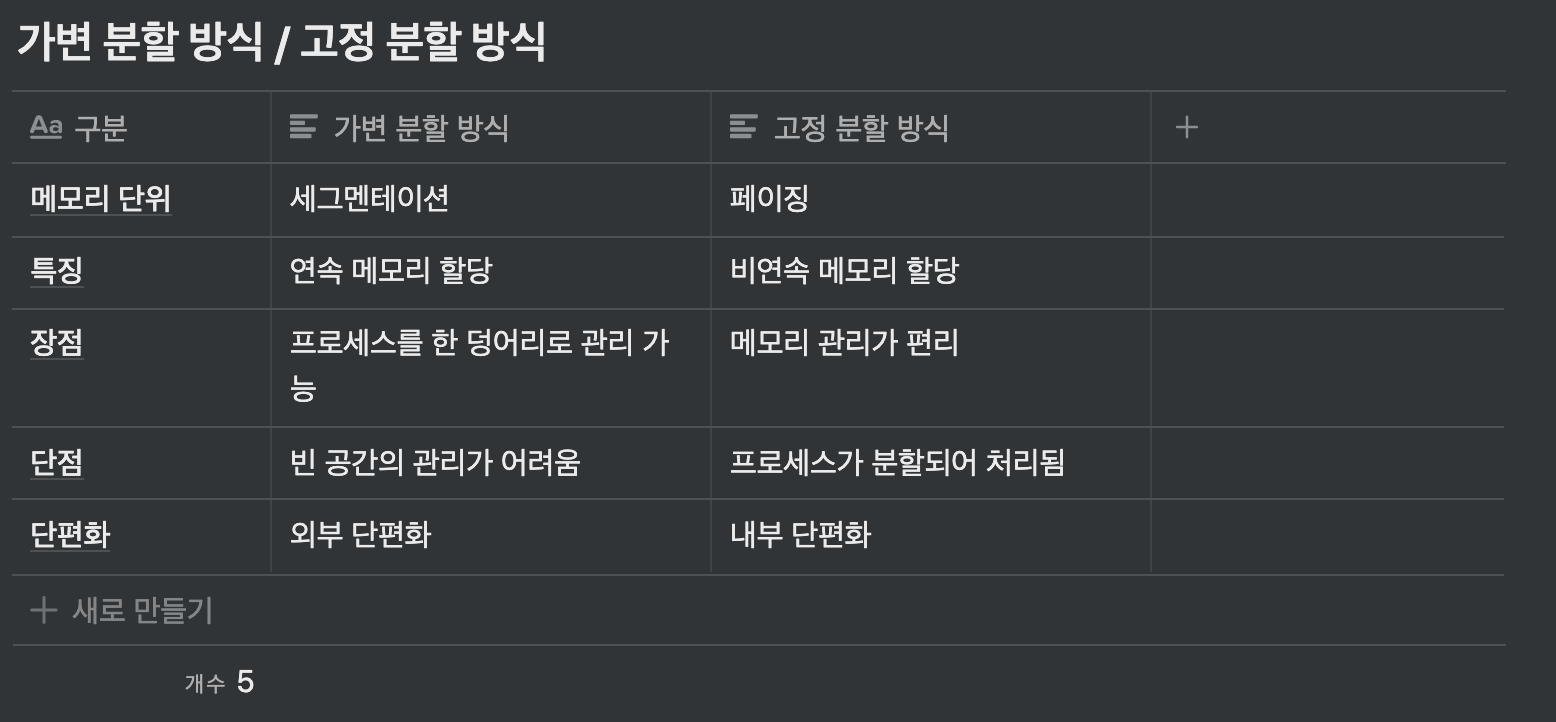
### 메모리 분할 방식
- 메모리를 어떤 크기로 나눌 것인지에 대한 정책 수립 → 메모리 배치 정책
- 크게 가변 분할 방식 / 고정 분할 방식으로 나눌 수 있음
- 요즘엔, 고정 분할 방식을 기본으로 사용하고, 필요한 부분에 가변 분할 방식을 혼합하여 사용 중
- 가변 분할 방식 ( Variable size partitionaing )
- 프로세스의 크기에 따라 메모리를 나누는 방식
- 식당에서, 손님의 크기에 따라 의자의 크기도 조정하는 방식
- 효율적인 방식 처럼 보이지만, 의자 관리 측면에서는 매우 불편
- 처리해야 할 프로세스가 메모리에 적재 되어야 할 때, 남는 메모리 공간이 없으면 공간이 나올 때 까지 대기
- 고정 분할 방식이 프로세스를 쪼개는 것과는 대비됨
- 식당에서 5명이 한 팀인 손님이 대기 중일 떄, 5명이 나란히 앉을 수 있는 자리가 나올 때 까지 손님 대기
- 만약, 식사중이신 손님 2명이 옆칸으로 이동 하면 5명의 자리가 난다면, 이동시켜야 5명이 한자리에 앉을 수 있지만 이는 매우 불편한 상황이 발생
- 프로세스의 크기에 따라 메모리가 분할 → 할당된 메모리의 영역이 각각 다름
- 한 프로세스가 연속된 공간에 배치되기 때문에, 연속 메모리 할당 이라고도 부름
- 장점
- 프로세스를 한 덩어리로 처리하여 하나의 프로세스를 연속된 공간에 배치
- 단점
- 메모리 관리가 복잡
- 대기중인 프로세스의 크기보다, 남는 메모리의 크기가 작은 경우에 프로세스의 공간을 위해 실행중인 프로세스를 이동 시킬 것인지, 등의 문제가 발생
- 메모리 관리
- 빈 영역이 있어도 서로 떨어져 있으면 프로세스를 배정하지 못하는 문제가 발생 ( 외부 단편화, external fragmentation )
- 이런 파편화 문제를 해결하기 위해 메모리 배치 방식 ( 작은 조각이 발생하지 않도록 프로세스를 배치하는 방식 ) / 조각 모음 ( 조각이 발생 했을때 작은 조각들을 모아 하나의 큰 덩어리로 만들어 주는 방식 ) 을 사용
- 메모리 배치 방식
- 최초 배치 ( first fit ) / 최적 배치 ( best fit ) / 최악 배치 ( worst fit ) 등이 있음
- 최초 배치
- 단편화를 고려하지 않고, 적재 가능한 공간을 순서대로 찾다가 첫 번째로 발견한 공간에 프로세스를 배치하는 방식
- 빈 공간을 찾아다닐 필요가 없다.
- 최적 배치
- 메모리의 빈 공간을 모두 확인 한 후 적당한 크기 가운데 가장 작은 공간에 프로세스를 배치하는 방식
- 빈 공간을 모두 확인하는 작업이 있지만, 파편화가 잘 일어나지 않는다는 장점이 있음
- 최악 배치
- 메모리의 빈 공간을 모두 확인 후 적당한 크기 가운데 가장 큰 공간에 프로세스를 배치하는 방식
- 프로세를 배치하고 남은 공간이 여전히 크기 때문에, 파편화를 줄일 수 있는 방식
- 조각 모음
- 작은 프로세스가 작업을 마치고 메모리에서 나가면 그 공간이 조각으로 남아 쓸모 없어질 가능성이 크기 때문에, 이미 배치된 프로세스를 옆으로 옮겨 하나의 큰 덩어리로 만드는 작업
- 여러개의 빈 공간을 합치는 작업
- 이동 할 프로세스의 동작을 멈추고, 이동시킨 뒤 상대 주소값을 바꾸어 주고, 프로세스를 재시작 하는 방식
- 많은 시간이 걸리며 메모리 관리가 복잡 해 짐
- 하드디스크의 조각 모음도 이와 비슷하게 동작
- 프로세스의 크기에 따라 메모리를 나누는 방식
- 고정 분할 방식 ( Fixed size partitioning )
- 프로세스의 크기와 상관 없이 메모리를 같은 크기로 나누는 방식
- 식당에서 손님의 신체 크기와 상관없이 같은 크기의 의자를 준비하는 방식
- 만약 손님이 의자보다 크면, 의자를 두개 / 세개 … 줌
- 비효율 적으로 보이지만, 의자 관리 측면에서는 매우 편함
- 나누어진 메모리 단위의 크기보다 프로세스의 크기가 큰 경우, 프로세스를 a, b, c등으로 쪼개어 분리
- 식당에서 5명이 한 팀인 손님이 대기 중이고 4명씩 앉도록 파티션이 되어 있다면, 따로 떨어져 앉더라도 5명이 앉을 수 있는 자리가 나오면 따로 떨어져 앉힘 ( 4 + 1 )
- 일행이 따로 앉는 문제를 신경 쓰지 않아도 되기 떄문에 관리에 수월
- 한 프로세스가 분산되어 배치되기 때문에 비연속 메모리 할당 이라고도 부름
- 장점
- 메모리 관리가 수월
- 단점
- 쓸모 없는 공간이 생길 수 있어 메모리 낭비가 발생 할 수 있음
- 나눠진 공간보다 작은 프로세스가 올라 올 경우, 남는 공간에 다른 프로세스가 할당 될 수 없으므로 메모리 낭비가 발생
- 메모리 관리
- 프로세스가 메모리의 여러 조각에 나뉘어 저장되는것이 문제
- 나뉜 메모리의 크기보다 작은 프로세스가 배치 될 경우 낭비되는 공간이 생기는 문제가 발생
- 일정한 크기로 나뉜 파티션 안쪽으로 작은 조각들이 발생 ( 내부 단편화, inner fragmentation )
- 가변 분할 방식에서 처럼 조각 모음을 할 수도, 남는 공간을 다른 프로세스에 할당 할 수도 없음
- 동일하게 분할되는 공간의 크기를 조절하여 내부 단편화를 최소화 하는 방향으로 최적화 ( 정답은 없으며, 이를 최적화 하는 방식은 여러가지 )
- 프로세스의 크기와 상관 없이 메모리를 같은 크기로 나누는 방식
### 버디 시스템
- 가변 분할 방식 / 고정 분할 방식의 중간 구조
- 작동 방식
- 프로세스의 크기에 맞게 메모리를 반으로 계속 자르고, 알맞은 크기에 프로세스를 배치
- 16개의 의자가 있을 때, 손님 세명이 오면, 4개의 파티션에 손님 세명을 앉힘
- 나뉜 메모리의 각 구역에는 프로세스 하나만 배치
- 윗 과정에서 나온 나머지 한 자리엔 손님을 앉히지 않음
- 프로세스가 종료 되면, 주변의 빈 조각과 합쳐서 하나의 큰 덩어리를 만듬
- 손님 세명이 나가면, 주변에 남는 의자들과 합쳐 하나의 덩어리를 만듬
- 프로세스의 크기에 맞게 메모리를 반으로 계속 자르고, 알맞은 크기에 프로세스를 배치
- 가변 분할 방식 처럼 메모리가 프로세스의 크기대로 나뉘며, 고정 분할 방식처럼 하나의 구역에 다른 프로세스가 들어 갈 수 없고 내부 단편화가 발생
- 비슷한 크기끼리 모이는 경우가 잦으므로, 메모리 통합이 쉬움
- 하지만, 작동 방식이 고정 분할 방식이 훨씬 단순하므로, 고정 분할 방식을 더 많이 사용하고 있음
"Operation System" 카테고리의 최근 포스팅
카테고리 모든 글 보기| 운영체제 스터디 (13) - 네트워크와 분산 시스템 | 2021. 03. 14 |
|---|---|
| 운영체제 스터디 (12) - 파일 시스템 | 2021. 03. 14 |
| 운영체제 스터디 (11) - 입출력 시스템과 저장 장치 | 2021. 03. 11 |
| 운영체제 스터디 (10) - 가상 메모리 관리 | 2021. 03. 10 |
| 운영체제 스터디 (9) - 가상 메모리의 기초 | 2021. 03. 08 |
| 운영체제 스터디 (8) - 물리 메모리 관리 | 2021. 03. 07 |
| 운영체제 스터디 (7) - 교착상태 | 2020. 12. 04 |
| 운영체제 스터디 (6) - 프로세스 동기화 | 2020. 11. 10 |
| 운영체제 스터디 (5) - interrupt | 2020. 10. 20 |
| 운영체제 스터디 (4) - CPU 스케줄링 | 2020. 10. 19 |