운영체제 스터디 도중 쉽게 배우는 운영체제를 읽고 요약한 내용입니다. 자세한 내용은 책을 구매하여 확인 부탁드립니다.
3. 프로세스와 스레드
프로세스의 개요
프로세스 vs 프로그램
요리사 모형에 빗댄 프로세스의 여러 상태
- 업장의 주문서 에는 주문 순서를 알려주는 일련번호, 테이블번호, 어떤 요리인지 등 작업 해야할 것들에 대한 세부 정보가 담겨 져 있음
1. 일괄 작업 방식
- 레스토랑에 하나의 테이블만 있는 것
- 손님이 식사를 마치고 나가야만 다른 손님을 받을 수 있음
- 작업 효율의 저하
- 손님에게 미리 주문을 받아 놓는다고 가정 시 미리 받은 주문에 대한 주문서를 Queue에 저장 함
2. 시분할 작업 방식
- 개선점
- 일괄 작업 방식에서는 손님이 식사하는 동안 다른 손님의 요리를 만들 수 없었음, 하지만 시분할 작업 방식에서는 첫번째 손님이 식사하시는 동안 두번째 손님의 식사를만들어 제공 할 수 있음
- 요리사는 한명이지만, 시간을 쪼개어 동시에 실행 하는 것 처럼 보이게 해줌
- 주문 처리 방식
- 여러 손님들에게 주문서를 미리 받음
- 주문 받은 주문서에 있는 여러 요리 중에 한가지를 만든 뒤, 다 만들어 지면 해당 주문서를 맨 뒤로 옮김
- 그 다음번 주문서를 가져와 요리를 시작
- 주문서에 있는 모든 요리가 제공 되면, 주문서를 삭제
- 주문서가 주문 목록에 올라 오는 것 → 요리의 시작을 의미
- 요리사가 요리 하는 동안, 주문서는 주문 목록에서 대기하거나, 요리사가 요리하는 상태를 왕복
- 주문 목록의 삭제 → 해당 요리는 종료 됨
- 대기 목록 / 보류 목록
- 대기목록
- 새우 튀김을 해야 하는데, 새우가 손질 되지 않은 상황을 가정
- 효율적으로 일하기 위해 보조 요리사에게 새우를 손질하라고 지시 한 뒤 그 다음 요리 시작, 새우가 다 손질 되면 신호를 받음
- 대기 목록은, 새우 손질이 끝날 때 까지 주문서 ( 작업 )가 기다리는 공간
- 손질이 완료 되면, 진행하던 요리를 멈추는 것은 비효율 적이므로 대기 목록에 있던 작업을 주문 목록으로 이동하여 다음 순서를 기다림
- 보류 목록
- 언제 다시 시작될 지 모르는 주문서가 기다리는 공간
- 보류 목록에 있던 주문서에 해당하는 손님이 음식을 달라고 하면, 보류 목록에 있는 주문서를 다시 주문 목록으로 보냄
- 손님이 주문을 폐기하면, 주문서를 폐기
- 언제 다시 시작될 지 모르거나, 중간에 그만 둘 지 모르는 작업들이 여기에 담김
- 대기목록
프로그램에서 프로세스로의 전환
- 프로세스
- 컴퓨터 시스템의 작업 단위, Task로도 불림
- 요리
- 요리의 주문서에 해당하는 작업 지시서를 제작
- 이 작업 지시서에는 주문 사항에 대한 상세 정보들이 담겨 져 있음
- 주문서가 없으면 요리가 진행되지 못함
- 컴퓨터
- 프로세스의 작업 지시서에 해당하는 프로세스 제어 블록을 제작
- 프로세스 제어 블록에는 프로세스를 처리하는데 필요한 다양한 정보들이 담겨 져 있음
- 프로세스 제어 블록이 없으면 프로그램이 프로세스로 전환되지 못함
- 프로세스 구분자, 메모리 관련 정보, 각종 중간값 등이 들어 있음
- 프로세스 ID
- 메모리에는 여러개의 프로세스가 존재
- 프로세스 ID는 각 프로세스를 구분하는 ID 값
- 메모리 관련 정보
- 실행하려는 프로세스의 메모리 위치에 대한 정보
- 메모리 보호를 위한 경계 레지스터, 한계 레지스터도 담겨 져 있음
- 각종 중간값
- 어떤 요리까지 손님에게 제공 되었는지 주문서에 표기하는 것과 유사
- 프로세스가 사용했던 중간 세이브 지점에 대한 데이터
- 프로세스 ID
- 운영체제가 해당 프로세스를 관리하기 위해 만들어진 데이터 구조 이기 때문에, 운영체제 영역에 존재
- 프로세스가 종료되면, 프로세스 제어 블록도 폐기
프로세스 = 프로그램 + 프로세스 제어 블록 ( 프로그램이 운영체제로 부터 프로세스 제어 블록을 얻은 상태 )
- 사용자가 실행 한 프로그램만 메모리에 올라 와 있는 것이 아님 ( 운영 체제도 프로그램, 부트스트랩 참조 )
프로세스의 상태
- 시분할 시스템에서는, 단품 요리를 번갈아 가며 요리를 하는 과정과 같기 때문에, 프로세스의 상태가 다양함
- 활성 상태
- CPU 스케줄러
- 준비 단계에 있는 여러 프로세스 중, 실행 상태에 갈 프로세스를 선정하는 작업은 CPU 스케줄러가 담당
- 해당 CPU 스케줄러의 작업을 dispatch라고 명명
- CPU 스케줄러는 프로세스의 전 상태를 관리
1. 생성 상태 - 프로세스가 메모리에 올라 와 실행 준비를 완료 한 상태
- 프로세스를 관리하는 데 필요한 프로세스 제어 블록을 운영체제로 부터 할당 받은 상태 2. 준비 상태
- 생성 된 프로세스가 CPU를 얻을 때 까지 기다리는 상태
- CPU는, 한번에 한가지 일을 처리 할 수 있기 때문에 생성 상태에 있는 프로세스는 본인의 CPU 순서가 올 때 까지 대기해야 하는데, 이 상태를 준비 상태라고 명명
- ready queue에 프로세스 제어 블록이 쌓여 져 있음
- 준비 상태에 있는 프로세스를 실행 상태로 옮기는 작업을 Dispatch 명령으로 처리 3. 실행 상태
- 준비 상태에 있는 프로세스 중 한가지가 CPU를 얻어 실제 작업을 수행하는 상태
- 일정 시간 동안 CPU를 사용 할 권리를 얻으며, 이 시간 동안 작업을 완료하지 못했다면 ( 프로세스 제어 블록에 남은 작업이 있다면 ) 프로세스를 다시 준비 상태로 옮김
- 타임아웃
- 위에서 말한 일정 시간을 타임 퀀텀, 타임 슬라이스 라고 칭함
- 이 시간 동안 작업을 완료하지 못해 준비상태로 프로세스가 돌아가는 것을 타임아웃 이라고 칭함
- CPU는 클록에 타임 슬라이스가 흐른 뒤 알려달라고 알림을 요청
- 이 클록에서 부터 온 인터럽트가 타임 아웃
- 실행 상태에 들어가는 프로세스는 CPU의 개수와 같음
- 타임 슬라이스 동안만 작업 가능하고, 타임 아웃이 발생하면 timeout 명령이 발생, 이 명령어는 프로세스 제어 블록은 실행 상태에서 준비 상태로 옮김
- 프로세스가 입출력을 요청하면 block 명령어로 대기 상태로 보냄 4. 완료 상태
- 실행 상태의 프로세스가 주어진 시간 동안 작업을 마친 상태
- 프로세스 제어 블록이 사라진 상태
- 코드와 사용했던 데이터를 메모리에서 삭제, 프로세스 제어 블록을 폐기
- 비정상 적으로 종료 되었다면, 종료 직전의 메모리 상태를 저장 장치로 옮겨 디버깅 가능하게 해줌 ( core dump 작업 ) 5. 대기 상태
- 실행 상태에서 프로세스가 입출력을 요구하는 상황을 상정
- 이는 요리사 모형에서 재료 준비가 안된 상황이랑 유사 → 재료 준비가 되면 알려달라고 하고 작업을 대기 상태로 보냄
- CPU는 입출력 관리자에게 데이터 입출력을 명령하고, 이 프로세스를 대기 상태로 보냄
- 즉 대기상태는, 입출력을 요구한 프로세스가 입출력이 완료 될 때까지 기다리는 상태를 칭함
- CPU 스케줄러는 대기 상태로 프로세스가 이전되면, 준비 상태에 있는 프로세스를 실행 상태로 가져 옴
- 대기 상태에 있는 프로세스의 입출력 요청이 완료 되었다는 인터럽트를 받으면, 해당 프로세스를 다시 준비 상태로 옮김
- 입출력 장치 별로 마련된 큐에서 대기함
- 입출력이 완료 되면, wakeup 명령어로 대기 상태에서 준비 상태로 프로세스 제어 블록을 이동 시킴
- CPU 스케줄러
- 휴식 상태
- 프로세스가 작업을 일시적으로 쉬고 있는 상태
- 종료 된 것이 아니라, 실행을 잠시 멈춘 상태
- 사용하던 데이터, 제어 블록들이 메모리에 그대로 유지 되어 멈춘 지점부터 재 시작 가능
- 보류 상태
- 프로세스가 메모리에서 잠시 쫓겨난 상태
- 일시 정지 상태로도 불림
- 보류 상태의 예제
- 메모리가 꽉 차서 일부 프로세스를 메모리 밖으로 내보낼 때
- 프로그램에 오류가 있어 실행을 미루어야 할 때
- 악의 적인 공격을 하는 프로세스라고 판단 될 때
- 대부분이 컴퓨터의 성능을 떨어뜨리거나, 실행을 미루어도 큰 지장이 없는 프로세스들
- 메모리 밖으로 쫓겨나 swap area에 보관 됨
- 보류 대기 상태
- 대기 상태에서 옮겨진 보류 상태
- 재시작 시 대기 상태로 돌아감
- 이 상태에서 입출력이 완료되면, 보류 준비 상태로 이동 됨
- 보류 준비 상태
- 준비 상태에서 옮겨진 보류 상태
- 재시작 시 준비 상태로 돌아감
프로세스 제어 블록과 문맥 교환
프로세스 제어 블록
- 프로세스를 실행 하는데 필요한 중요 정보를 보관하는 자료 구조
- 모든 프로세스는 고유의 프로세스 제어 블록을 가지고 있음
- 프로세스 실행 완료 시 폐기
- 프로세스 제어 블록 구성 요소
- 포인터
- 준비 상태, 대기 상태에서는 Queue의 형태로 프로세스 제어 블록이 관리 되는데, 이 Queue를 구현하기 위해 존재
- 대기 상태에서는 같은 입출력을 기다리는 프로세스 끼리 Queue를 구성 → 각 queue를 Ready queue라고도 부름
- 프로세스 상태
- 프로세스가 현재 어떤 상태 ( 생성 상태, 준비 상태, 실행 상태 … )에 있는 지에 대한 정보
- 프로세스 구분자
- 여러 프로세스를 구별하기 위한 구분자를 저장 ( ID )
- 프로그램 카운터
- 다음에 실행 될 명령어의 위치를 가리키는 프로그램 카운터의 값을 저장
- 프로세스 우선순위
- 준비 상태에서 Queue는 여러 개임
- 이 때 우선 순위별로 queue가 배정되고, 프로세스 제어 블록이 담긴다
- 높은 우선순위의 프로세스가 더 자주 실행되고, 먼저 실행된다
- 각종 레지스터 정보
- 프로세스가 실행 되는 중에 사용하던 레지스터에 대한 정보
- 해당 값을 보관해야 다음에 해당 값부터 실행 가능 하기 때문에 레지스터의 중간값을 저장
- 메모리 관리 정보
- 프로세스의 메모리 위치에 대한 정보, 메모리 보호를 위해 사용하는 경계 레지스터, 한계 레지스터 값 등이 저장
- 할당된 자원 정보
- 프로세스를 위해 사용 되어야 하는 입출력 자원, 파일 등에 대한 정보
- 접근 해야할 저장 장치, 사운드 카드에 대한 정보가 저장 됨
- 계정 정보
- CPU 할당 시간, CPU 사용 시간 등에 대한 정보
- 부모 프로세스 id, 자식 프로세스 id
- PPID ( Parent PID ), CPID ( Child PID )정보가 저장 됨
- 포인터
- 문맥 교환 ( Context switching )
- 요리
- 한가지 요리를 마친 뒤, 주문서를 교환하는 작업이 진행 됨
- 이때, 주문서 교환 뿐 아니라 이전의 요리를 위해 준비 했던 재료들을 정리 해야 한다.
- 즉, 주문서를 바꾸는 것과 동시에 환경을 바꾸는 작업
- 컴퓨터
- CPU를 차지하던 프로세스가 나가고, 새로운 프로세스를 받아들이는 작업을 칭함
- 프로세스 제어 블록의 내용이 변경 됨
- 이전의 프로세스 제어 블록 에는 지금 까지 진행 되었던 작업 내용을 기록 하고, 실행 상태로 들어오는 프로세스 제어 블록의 내용을 CPU에 세팅
- 위의 일련의 작업을 Context switching ( 문맥 교환 ) 으로 칭함
- 한 프로세스의 타임아웃이 일어 났을 때, 인터럽트가 발생 했을 때 등의 경우에서도 문맥 교환이 발생 함
- 요리
스레드
- 요리 모형
- 요리를 완성하는 전체 과정 → 프로세스
- 요리를 완성하기 위해 수행하는 각각의 조리과정 → 스레드
- 운영체제는 프로세스를 관리하고, CPU는 프로세스 속 구체적 작업 단위인 스레드를 작업한다.
- 스레드 ( 하나의 작업 단위 )가 모여 프로세스가 작업 된다. ( 집짓기 : 프로세스, 토지 구매 / 설계 등등 … : 스레드 )
- 프로세스, 스레드 간의 통신
- 프로세스
- 요리 모형
- 각 요리들은 연관성이 별로 없음
- 요리들의 순서를 바꿔도 크게 지장 없을 수 있음
- 프린터, 워드프로세서 예제
- 워드프로세서가 멈춰도 프린터의 스풀러는 계속 작업 할 수 있음 ( 멀티 태스크 )
- 서로 독립적 일 수 있음
- IPC ( Inter Process Communication )을 이용하여 프로세스 끼리 통신 할 수 있음
- 요리 모형
- 스레드
- 프로세스 내부에서 서로 강하게 연결 되어 있음
- 요리 모형
- 스테이크 / 야채를 구운 뒤에 소스를 뿌려야 함
- 각 스레드들은 인과관계가 존재 할 수도 있으며, 여러 상관 관계가 존재 할 수 있음
- 워드 프로세서 예제
- 문서 편집, 문서 입출력 등 동시에 작업을 할 수 있음
- 스레드들은 강하게 연결 되어 있음
- 프로세스
- 스레드 관련 용어
- 멀티 스레드
- 프로세스 내 작업을 여러 개의 스레드로 분할하여 작업의 부담을 줄이는 기법
- 소프트웨어 적인 기법
- 멀티 태스킹
- 운영체제가 CPU에 작업을 줄 때 시간을 잘게 나누어 배분하는 기법
- 이런 시스템을 시분할 시스템이라고 함
- CPU에 작업을 줄 때 스레드를 준다
- 멀티 프로세싱
- CPU를 여러 개 사용하여 여러 개의 스레드를 동시에 처리하는 작업 환경
- 하나의 CPU에 여러개의 코어에 스레드를 매칭하여 멀티 프로세싱 환경을 구축 할 수 있음
- CPU 멀티 스레드
- 한번에 하나씩 스레드를 처리하는 것을, 파이프라인 기법을 이용하여 동시에 여러 스레드를 처리하도록 만든 병렬 처리 기법
- 하드웨어 적인 기법
- 멀티 스레드
멀티 스레드의 구조와 예
- 멀티스레드
- C언어 등의 초기 언어는, 여러개의 작업을 동시에 처리하기 위해 fork로 똑같은 프로세스를 생성 하거나, exec 호출로 프로세스 전환 하는 방법을 이용함
- 코드 영역과 데이터 영역의 일부가 메모리에 중복되어 존재 할 수 있음
- 워드프로세서를 여러 개 띄워 놓고 작업을 할 때, 각 워드 프로세서를 fork로 생성 할 수 있음
- 이 경우엔, 워드 프로세서의 코드 일부, PCB, 공유 변수 등이 여러곳에 중복 됨
- 스레드를 통해 코드, 데이터 등을 공유하며 여러개의 일을 하나의 프로세스에서 처리 하면 위와 같은 멀티 태스킹의 낭비 요소를 제거 할 수 있음
- 프로세스
- 정적인 영역 : 프로세스가 실행 되는 동안 바뀌지 않는 영역 ( 코드, 전역 데이터, 파일 … )
- 동적인 영역 : 스레드가 작업을 하면서 값이 바뀌거나 새로 만들어지거나 사라지는 영역 ( 레지스터 값, 힙 … )
- fork를 통해 프로세스를 새로 생성하면, 정적 + 동적 영역 모두 새로 할당 됨
- 스레드를 통해 다른 작업을 진행 할 땐, 정적 영역은 공유 한 채 동적 영역만 변경 하여 다른 작업을 진행 할 수 있음
- 멀티 스레드의 장단점
- 장점
- 자원의 낭비를 막을 수 있음
- 작업의 효율을 높일 수 있음
- 어떤 작업을 진행 하는 동안, 다른 작업을 진행 할 수 있음
- 채팅을 하면서 파일을 주고 받기
- 문서를 편집 하면서 틀린 글자를 찾는 작업을 독립적으로 진행
- 응답성 : 한 스레드가 작업이 진행 되고 있지 않더라도, 다른 스레드가 작업을 계속할 수 있음
- 자원 공유 : 한 프로세스 내에서 공유적인 자원 사용 가능 ( 정적인 영역 )
- 다중 CPU 지원 : 2개 이상의 CPU가 있는 컴퓨터 에서는, 다중 CPU가 멀티 스레드를 동시에 처리 할 수 있는 환경이 됨
- 단점
- 모든 스레드가 자원을 공유하기 때문에, 한 스레드에 문제가 생기면 전체 프로세스에 영향을 미친다.
- 인터넷 익스플로러에서 화면을 하나 강제 종료하면 전체 종료되는 경우
- sequal pro에서 한 탭이 제거되면 다른탭 다 제거되는 것등을 생각 해 볼 수 있음
- 프로세스는 하나인데, 프로세스가 문제가 생기면 프로세스속 스레드가 모두 제거되는 것임
- 낭비가 있더라도 안정성을 위해서 멀티 태스킹을 이용 할 수 있음
- 모든 스레드가 자원을 공유하기 때문에, 한 스레드에 문제가 생기면 전체 프로세스에 영향을 미친다.
- 장점
멀티 스레드 모델
- 프로세스 → 커널 프로세스 / 사용자 프로세스로 나눌 수 있음
- 커널 프로세스 : 커널이 직접생성하고 관리하는 스레드
- 사용자 스레드 : 라이브러리에 의해 구현된 일반적인 스레드
- 사용자 스레드
- 운영체제가 멀티 스레드를 지원하지 않을 때 사용하는 방법
- 유저가 만든 라이브러리를 사용 하므로, 커널 입장에서는 하나의 일반적인 프로세스임
- 우리가 일반적으로 개발 할 때 쓰는 Thread가 이 스레드임
- 사용자 프로세스 내에 여러개의 스레드가 존재 하지만, 이는 라이브러리 에서 구현된 스레드 이므로 하나의 커널 스레드에만 연결 된다.
- 1 to N 모델으로도 지칭 함
- 장점
- 라이브러리가 직접 스케쥴링, 작업에 필요한 정보를 처리 하기 때문에 Context switching이 필요 없음 … ?
- 커널에 독립적으로 스케쥴링 가능
- 커널 영역의 오버헤드가 줄어 듬
- 응용 프로그램에 맞게 최적화 가능
- 단점
- 커널 스레드가 대기 상태에 들어가면, 모든 사용자 스레드가 대기 상태가 됨
- 한 프로세스의 타임 슬라이스를 여러 스레드가 공유 하기 때문에, 여러개의 CPU를 동시에 사용 할 수 없다.
- 보안에 취약 ( 커널 레벨과 사용자가 직접 구현한 것에서 오는 차이 )
- 쓰레드간 보호를 따로 제공 해 주어야 한다
- 커널 스레드
- 커널이 직접 멀티 스레드를 지원하는 방식
- os가 관리하는 스레드들에 사용자 스레드가 1:1로 매핑 됨
- 특정 스레드가 대기 상태에 들어가도 다른 스레드들은 작업이 가능 함
- 멀티 CPU가 사용 가능 하나, Context switching 시 오버헤드가 발생 가능
- 사용자 스레드를 생성하면, 이에 대한 커널 스레드가 자동 생성 됨
- 멀티 레벨 스레드
- M to N 모델, 커널 스레드의 갯수가 사용자 스레드의 갯수보다는 적음
- 각 프로세스에는, 경량 프로세스가 존재
- 각 프로세스 속 사용자 스레드는, 경량 프로세스와 N:1으로 매핑 됨
- 경량 프로세스는 커널 스레드와 1:1로 매핑됨
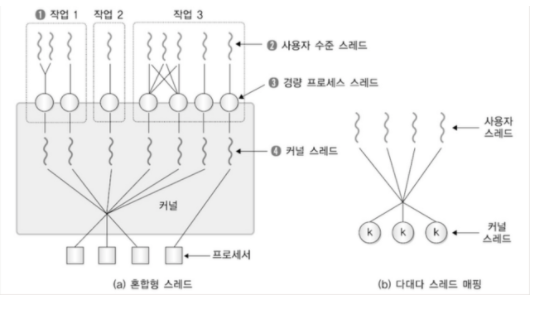
출처 : https://coding-start.tistory.com/199
동적 할당 영역과 시스템 호출
- 프로세스
- 프로세스 → 정적 할당 영역 ( 코드 영역 + 데이터 영역 ) + 동적 할당 영역 ( 스택 영역 + 힙영역 )
- 정적 할당 영역
- 포인터를 제외한 변수는 선언 할 때 그 크기가 결정 됨
- 따라서 프로세스가 실행되기 직전에, 위치와 크기가 대부분 결정 되고 변하지 않으므로 정적 할당 영역이라고 칭함
- 동적 할당 영역
- 프로세스가 실행 되는 동안 만들어 지는 영역
- 크기가 늘어났다가, 줄어들었다가 할 수 있는 영역
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int main() { int a = 1, b = 2; printf("main %d %d\n", a b); add(a,b); exit(); } add(int c, int d) { mul(c,d); printf("add %d\n", c+d); } mul(int e, int f) { printf("mul %d\n", e*f); }- 스택
- 함수 호출과 복귀 시에 스택이 사용 됨
- main이 프린트 되고, mul 함수가 동작 하고, add 함수가 끝나고, exit() 가 이루어 지는 형태가 stack의 형태
- add 함수가 호출 되면, 스택에 함수를 실행하고 되돌아올 위치 정보 ( 코드 실행 줄 )과, 함수에서 사용하는 지역변수 c,d를 입력 ( push )
- mul 함수가 호출 되면, 스택에 함수를 실행하고 되돌아올 위치 정보 ( 코드 실행 줄 )과, 함수에서 사용하는 지역변수 e,f를 입력 ( push )
- mul 함수가 종료 되면, 스택에서 제거 ( pop )
- 2에서 스택에 넣은 되돌아올 위치 정보에 코드가 되돌아 옴
- add 함수가 종료 되고, 스택에서 제거 ( pop )
- 1에서 스택에 넣은 되돌아올 위치 정보에 코드가 되돌아 옴
- main이 프린트 되고, mul 함수가 동작 하고, add 함수가 끝나고, exit() 가 이루어 지는 형태가 stack의 형태
- Variable scope를 구현 할 때 사용 됨
- 함수 속에서 사용하는 지역 변수는, 함수가 호출 될 때만 사용 되다가 종료되면 사용된 공간을 반환 해야 하는데, 이 지역 변수를 저장 할 때 stack의 형태를 사용함
- 어떤 함수가 사용 될 지는 컴파일 시 알 수 있지만, 몇번 사용될 지는 런타임에서 알 수 있음 ( 계산기 예제 생각 ) → 스택은 동적 영역임
- 모든 코드를 main()에 집어 넣고, 함수 호출을 최소화 하면 stack 유지 비용이 줄어들어 속도가 빨라 짐
- 하지만 유지보수 … → 느리더라도 함수 사용
- 함수 호출과 복귀 시에 스택이 사용 됨
- 힙
- 프로그램이 실행 되는 동안 크기가 할당 되는 malloc 함수를 생각
1
2
3
4
5
6main() { int sarr[50]; int *darr; darr = (int*)malloc(sizeof(int)*50); free(darr); }- 프로그램 실행시에, sarr은 int 50개 만큼의 크기를 차지
- darr 포인터 변수는 아직 얼만큼 크기를 차지 할 지 정해지지 않음 → 빈상태
- malloc을 만나면, darr은 메모리에 자리를 차지함 → 힙 영역에 정수 50개 만큼의 공간을 배정 해 준다
- sarr은 데이터 영역, darr은 힙 영역에 저장 된다.
- sarr은 프로세스가 종료 될 때 까지 메모리를 차지
- darr은 필요할 때 메모리를 할당 받고 ( by malloc ), free로 풀어줄 수 있음
- 워드프로세서의 문서 배열 크기는 정할 수 없기 때문에, malloc을 사용
- PCB를 구현한다면, 구조체 배열을 만들어 사용 하게 될 텐데, 크기를 미리 알 수 없으므로 동적 할당을 사용
exit() / wait()
-
Exit 시스템 호출
1
2
3
4main() { printf("Hello world! \n"); exit(0); }- main 함수의 끝에 exit(), return()을 사용 하는것은, 자식 프로세스가 끝났음을 부모 프로세스에 알리는 것
- exit() → 작업의 종료를 말해주는 호출
- Unix에서는, 모든 프로세스 생성을 init 프로세스를 fork / exec 하여 생성 하기 때문에, 부모 자식 관계가 항상 있음
- 이는 자원 회수를 용이하게 해줌
- exit() 함수는 부모 프로세스에 인자를 전달 할 수 있음, 위에선 0을 전달 ( 0이면 정상 종료, -1 이면 비정상 종료 )
-
Wait 시스템 호출
- 정리 해야 할 자식 프로세스를 정리 하지 않은 채 부모 프로세스가 종료 되면, 고아 프로세스, 좀비 프로세스가 생성 될 수 있음
- 따라서 wait() 호출을 사용 하여 이러한 것을 방지 함
- 부모 - 자식 프로세스 동기화를 위해서도 사용 됨
"Operation System" 카테고리의 최근 포스팅
카테고리 모든 글 보기| 운영체제 스터디 (13) - 네트워크와 분산 시스템 | 2021. 03. 14 |
|---|---|
| 운영체제 스터디 (12) - 파일 시스템 | 2021. 03. 14 |
| 운영체제 스터디 (11) - 입출력 시스템과 저장 장치 | 2021. 03. 11 |
| 운영체제 스터디 (10) - 가상 메모리 관리 | 2021. 03. 10 |
| 운영체제 스터디 (9) - 가상 메모리의 기초 | 2021. 03. 08 |
| 운영체제 스터디 (8) - 물리 메모리 관리 | 2021. 03. 07 |
| 운영체제 스터디 (7) - 교착상태 | 2020. 12. 04 |
| 운영체제 스터디 (6) - 프로세스 동기화 | 2020. 11. 10 |
| 운영체제 스터디 (5) - interrupt | 2020. 10. 20 |
| 운영체제 스터디 (4) - CPU 스케줄링 | 2020. 10. 19 |